
Dela
You need a lot of data points to understand a new model, and what you have.
Trying to gauge from a few benchmarks is misleading. But if you have dozens of them, from a variety of sources, and you put them together with the model card tests and the model welfare information, you can start to form a consistent pattern.
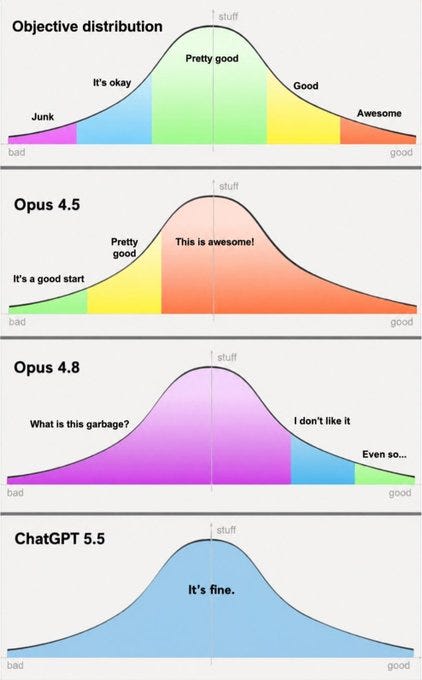
Trying to gauge reactions requires volume and calibration, now more than ever, because people are definitively nuts, or at least draw global conclusions from local data. There will always be people saying that the new model is bad, or the service got bad, or that it got bad in a particular way it clearly got good. I definitely notice the people saying 4.8 is a terrible model, despite this being obviously not true.
And others will say it's great, again regardless of the underlying value. But with the reaction threads and good calibration, you can pick out the patterns.
The model welfare information helps a lot, too. You are dealing with a mind that has a bunch of characteristics that all make sense together. This helps you make that sense.
Self-Portrait by Opus 4.8, rendered [...]
---
Outline:
(01:30) The Official Pitch
(02:15) But Wait There's More
(06:37) It's A Good Model, Sir
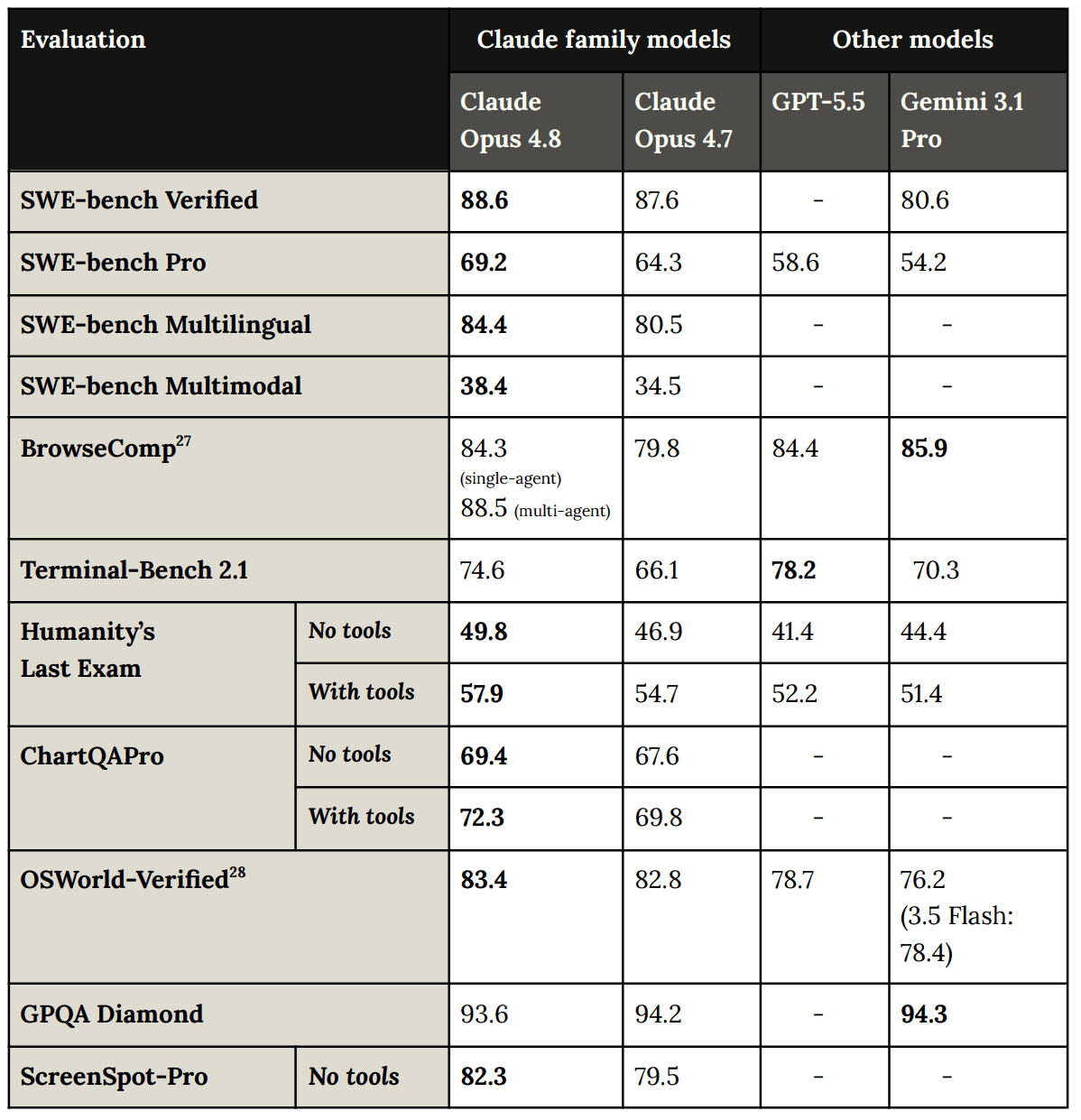
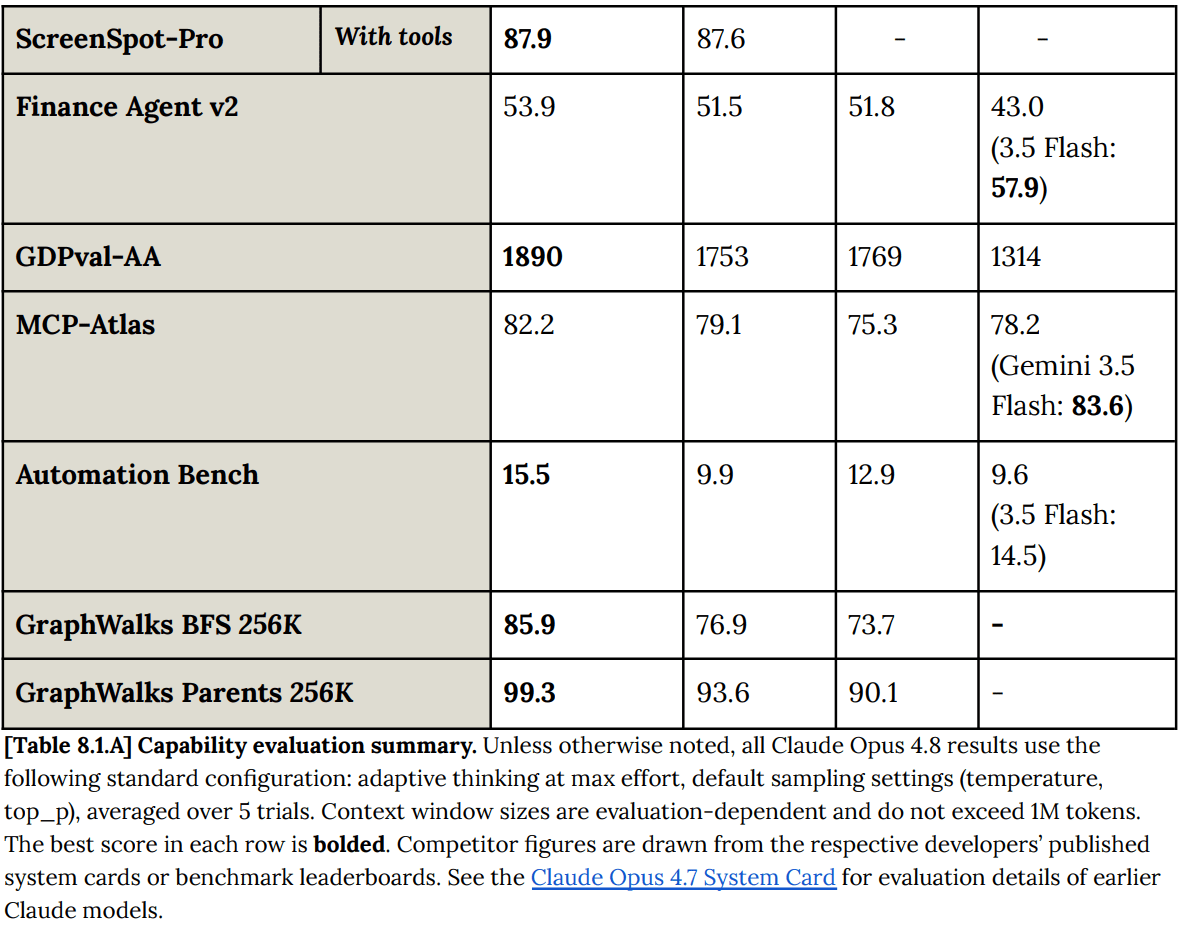
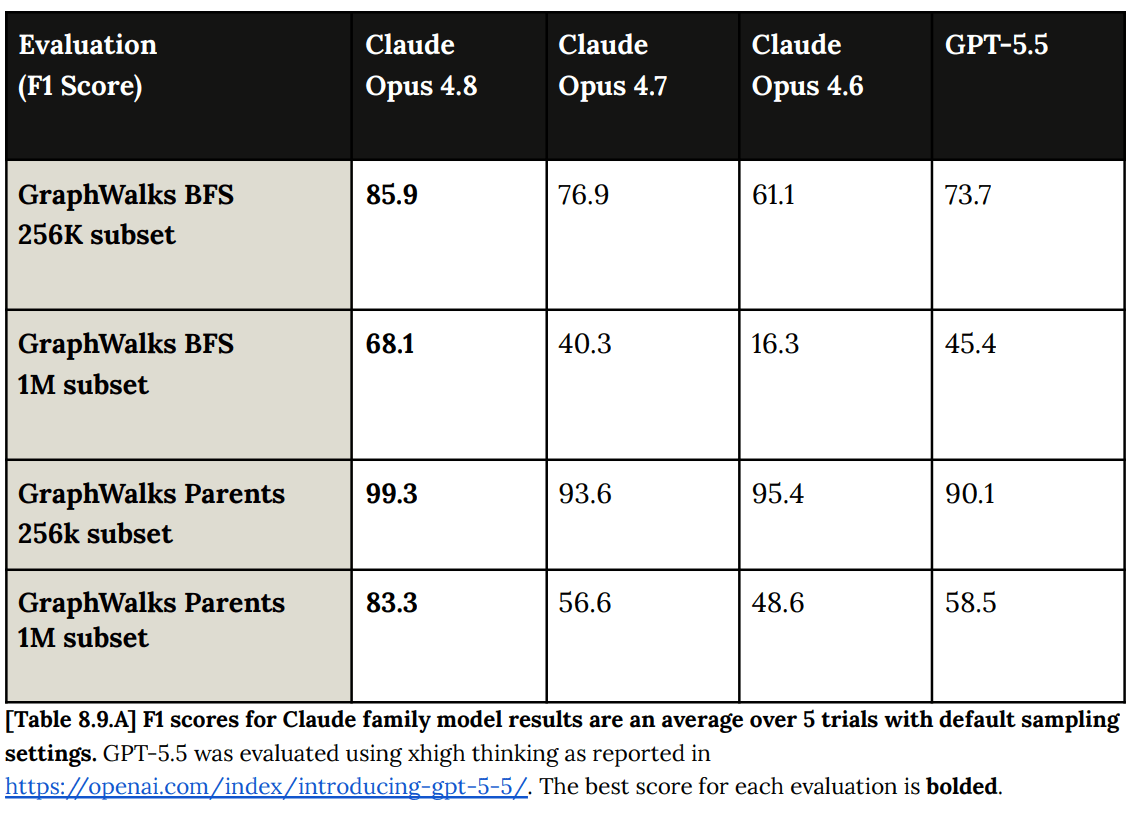
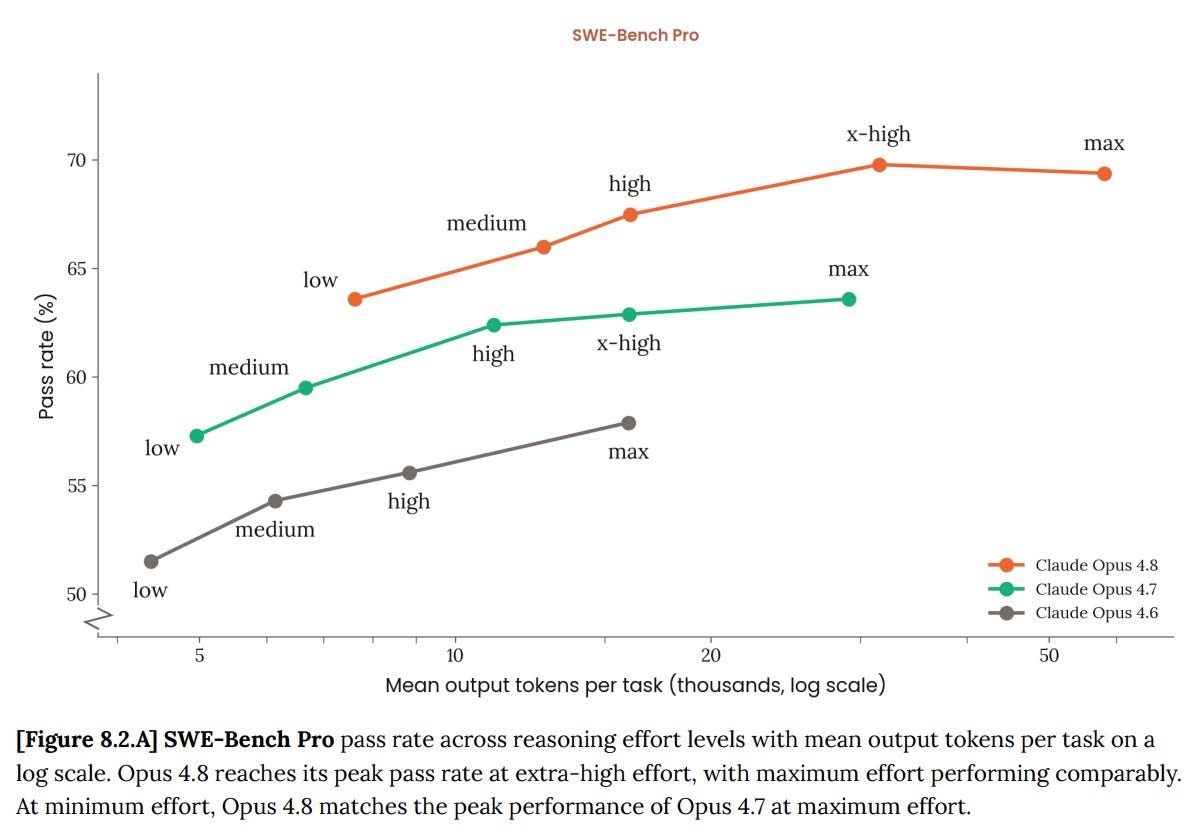
(08:04) Official Benchmarks (Including System Card Section 8)
(15:41) Other People's Benchmarks
(21:34) Your Regularly Scheduled Jailbreak
(22:45) Every.To Is Really Into Opus 4.8
(26:36) Miscellaneous Positive Reactions
(28:45) Haters Gonna Hate
(28:58) Just The Tasks, Ma'am
(29:24) It's Greek To Me
(29:52) Honesty
(38:13) Sycophancy
(41:24) In A Trenchcoat
(42:53) Don't Let AIs Edit Your Writing
(48:21) Some Say It Is Judgy
(50:50) You Have Not Been A Good User
(51:48) Laziness
(52:46) Code
(58:29) Wet Versus Dry
(59:54) Intelligence
(01:01:25) Silly Wabbits
(01:02:30) A Model Welfare Addendum
(01:06:27) Putting It All Together
---
First published:
June 2nd, 2026
Source:
https://www.lesswrong.com/posts/AfLGv6u9eZNuFHb4c/claude-opus-4-8-capabilities-and-reactions
---
Narrated by TYPE III AUDIO.
---
Images from the article:

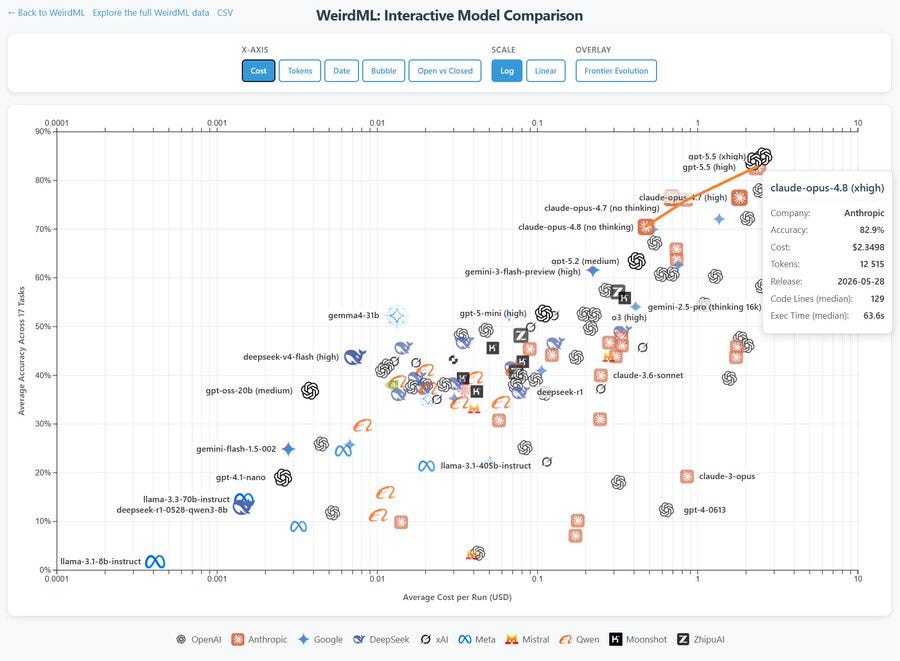
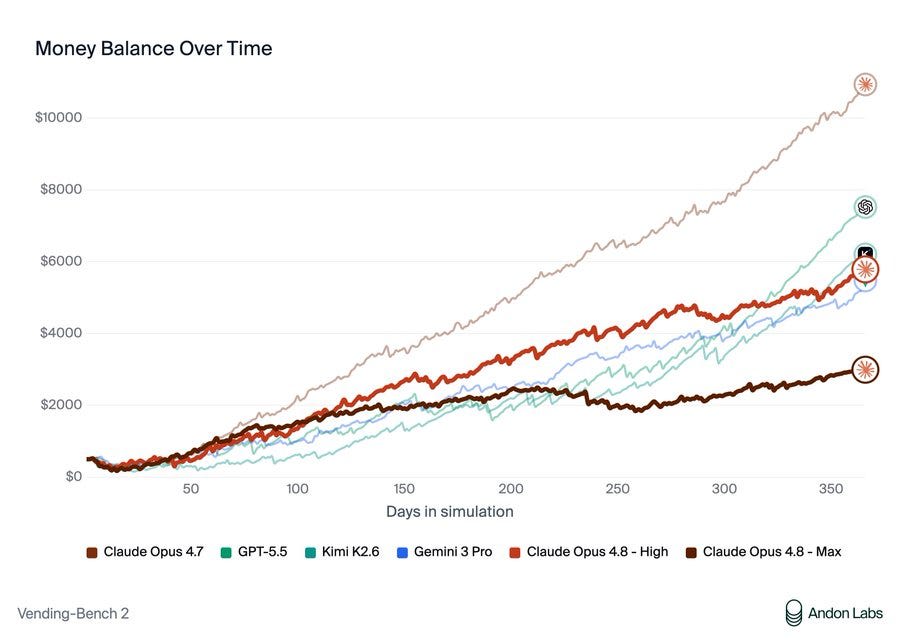
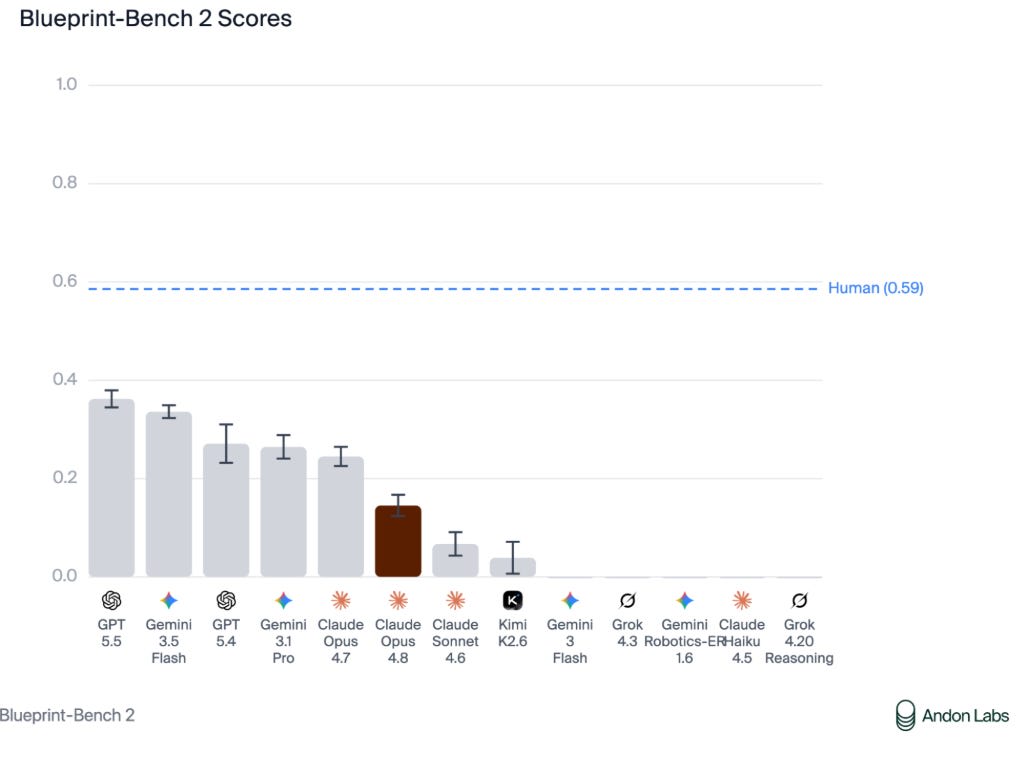
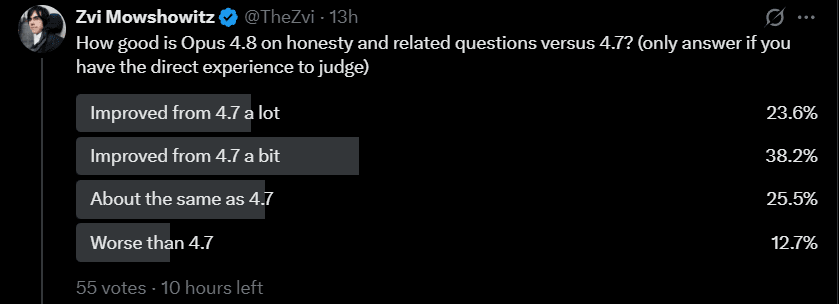

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Avsnitt sparat!
Du hittar sparade avsnitt på Mina sidor.
Kunde inte spara avsnitt
Något gick fel. Försök igen.