
Dela
在58同城约了个机器人上门做保洁,来的不只一台机器,还自带工程师、保洁阿姨和货拉拉司机。这一期不只有自变量的保洁机器人。去年在北美花60美金30分钟体验了一次机器人按摩,回头一查,那家叫Aescape的公司今年4月破产了。维他动力的Vbot机器狗也开始大规模交付了——4000台,占去年行业产能的五分之一。三段亲历,同一个问题:消费级机器人离"有用"到底还有多远?
后半段我们扎进了行业数据策略的争论。Jim Fan在红杉闭门会上说VLA已死,世界模型才是出路。我们还扒了最近Figure、Generalist、Genesis AI三家放出的demo——这些视频看起来一个比一个强,但在真实场景里的表现,我们存疑。
02:00 自变量机器人上门:149块3小时,谁在干活?
一台机器人进门要三个人伺候:工程师、阿姨、货拉拉司机。
58同城APP预约,目前只开放深圳。149元含一位保洁阿姨+一台双臂机器人+一位随行工程师。阿姨收拾厨房厕所卧室,机器人只负责客厅——过不了门槛、挤不进卧室。
机器人是轮式底盘,宽50cm长80cm高约1.5m,重几百公斤。两个夹爪能从地面夹到1.5m高,工程师得用货拉拉运、用斜坡推下车,"抱是抱不下来的"。
它在客厅干了这些活:把倒地书包拎起、拉上拉链(夹了3次)、三个书包摞一摞、叠了五六件衣服(每件5到10分钟)、茶几杂物归类后丢垃圾、餐桌杂物叠成半桌、临走把门口鞋摆好。中间死机一次,停了20分钟。
机器人完全静默——没有音响,零交互。托马斯白没法给它派活,"他进来就直奔沙发开始干,我没有做任何表达"。背部USB口插着一个4K HDMI发射器(用来回传画面和遥操指令),工程师自带了华为5G路由器组网。

10:00 拉拉链那一幕:惊艳是真的,推测有人在遥操
我给遥操的大哥点个赞了,手法真好。
书包拉链是拉上了。从地面拎包→放沙发→夹拉链(失败两次)→换到侧面夹→成功,整个过程2分多钟。动作精细程度远超目前任何全自主模型的公开水平。
托马斯白中间说了一句"这个可以放在旁边的箱子上",机器人大约2秒后转头找到那个箱子放下,感觉"后台有人在听"。
中间停住过一次,工程师查网络、联系公司,约20分钟恢复。
行业惯例:1X的人形机器人进家100%遥操,智元2025年展示的做三明治也是遥操,Tesla Optimus那次倒啤酒后来也被爆是遥操。Nixon:"凡是看起来太完美的家用机器人现场,默认它有遥操背景是更合理的判断。"
叠衣服的表现倒像自主尝试——不是人类叠法,不甩不抖,左抓右抓,叠得"比我儿子还差点"。托马斯白的猜测:拉拉链这类精细活是遥操,叠衣服这种标准化任务可能切到了世界模型在跑。皮沙发脚托很滑,衣服下半截接触台面后还会被拉移位。烘干后带皱的不同面料,跟实验室里轻薄垂顺的T恤完全是两码事。机器人没有"甩"这个动作能力——而叠好衣服恰恰需要抖和甩。最后那叠衣服只能说变成了方形,里面的皱褶全在。


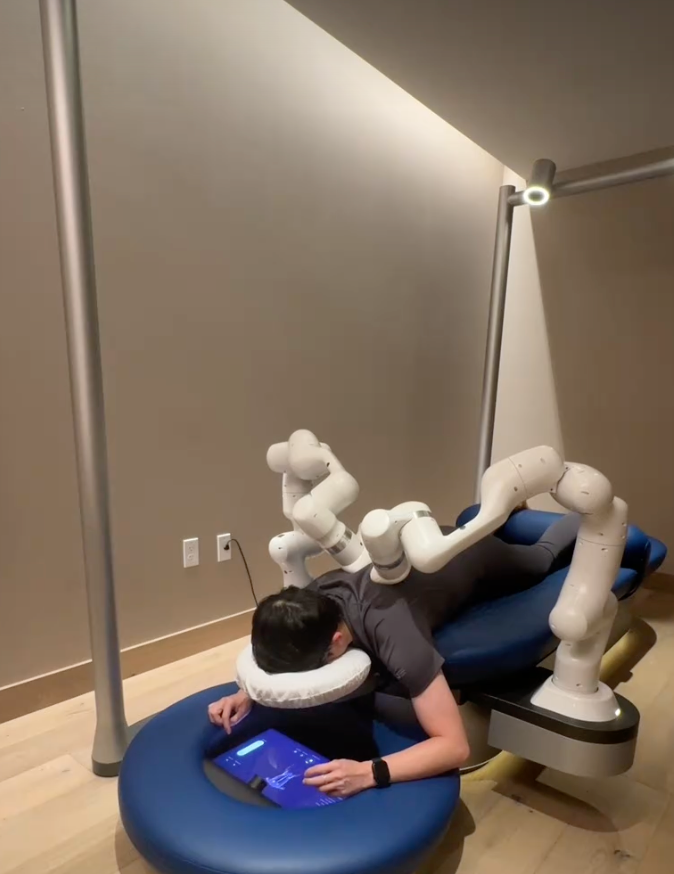
33:00 按摩机器人为什么死了?Aescape的1.57亿美金教训
像在工厂里被按摩。节奏、节拍、运行声都像车间设备。
Aescape,2017年成立,Equinox健身房和四季酒店有部署,30分钟60美元。上个月申请破产,累计亏了1.57亿美元,融了1.2亿,资不抵债。
Nixon去年10月体验:先上网填衣服尺码,到店换上紧身瑜伽服,摘掉项链摘项链、Body Scan,塞好衣角。躺在床上,左右两个"螃蟹钳子"机械臂开始从上到下、从轻到重地滚。咔特咔特的充放气声+散热风扇嗡嗡响,背景放着冥想音乐也盖不住。
力控粗糙。机械臂无法像人手一样一会儿用手掌一会儿用骨节调节压强,力道偏大时Nixon只能自己往下滑来躲。触觉也没精细到能感知衣服材质——所以才必须让客人穿统一面料,"用流程兜底感知能力不足"。
一周只能约三天,剩下四天机器在维护。"一台机器7天只干3天活,单店利用率直接腰斩。"商业模型里回本周期、维护成本、场地分成三项一算,根基本来就是裂的。
41:00 Vbot机器狗量产
5月8号首批500台下线,5-6月产能冲到2500台/月,四千台进家庭。Pre-A轮近5亿元,目前消费级具身赛道单笔最大。CEO已明确下一站在做全尺寸人形机器人。
Nixon在上海长宁来福士探店,商场草地和教堂广场上牵着遛了15分钟。四种跟随模式:稳态(要使点劲拽)、省力(手腕一转就跟)、户外探路(机器在前)、跟随(机器在后)。UWB信标=远程牵引绳+跟随定位锚,内置麦克风能语音查询"来福士到长宁区政府怎么走"。
新配件包括静音组、防夹手设计、家庭守护(本地48小时存储),后续Openclaw SDK路线是"模糊指令→自动编程→完成任务"。
4000台=去年行业机器狗总产能的1/5。Nixon:"量产是数据滚轮的入场券。硬件趋同后,操作系统和生态才是真正的护城河。"

45:00 数据游戏变了:从人手把手教,到iPhone绑头上拍
过去两年,行业靠VR遥操攒数据起家——让操作员戴着VR头盔用手柄控制机器人做动作,录下来当训练样本。这条路走到头了:单工位年运营50万+人民币,建1000个工位也凑不到100万小时;遥操员没触觉反馈,成功率只有1/3;动作慢、动作僵,抖衣服这种依赖速度的任务永远学不会。
2025年出现拐点。单目人体姿态估计成熟,iPhone第一人称视频能精准提取21个手部关节——戴着手机正常干活就能产训练数据。英伟达EgoScale的配方:2.1万小时ego视频做预训练(主食),加50小时数据手套(精细对齐),加4小时遥操(校准锚定,不到0.1%),就训出了符合scaling law的模型。
Build AI,一家18岁哥大辍学生创办的公司,把iPhone和头戴相机绑在亚洲数千名工厂工人头上。去年10月开源1万小时,年底扩到10万小时,今年目标100万小时。这本质上是把"采人类视频"做成了流水线生意。
三条线都在跑,只是权重在变:遥操→黄金数据(微调锚定用),ego视频→基础数据(预训练主粮),Human Data多模态→核心数据(力觉触觉全身动力学)。Jim Fan给的金字塔很直白:塔尖遥操最难扩展,塔基第一视角视频千万小时级别起步,"饭在塔基"。
01:00:00 Jim Fan的“暴论”:VLA已死,WAM当道
可乐罐放在Taylor Swift照片旁边——这是VLA最高光的demo,也是天花板。
VLA(Vision Language Action)的根子是让语言模型理解物理任务。Jim Fan在红杉闭门会上直接给VLA画了个墓碑RIP。原因很简单:"绝大部分参数给了语言",而语言在物理世界里是有损压缩——"把可乐罐放在Taylor Swift照片旁边"这种任务靠语义指代能行,"把这件衣服叠成刚好能塞进抽屉的样子""绕着这盆花的形状擦桌子"——全是"差不多""刚好""大概",文字编码不了。
WAM(World Action Model)替代思路:预测世界下一帧画面,让动作微调把预测兑现成执行。"如果模型预测的下一帧是对的,动作通常就是对的。"作品Dream Zero,Jim Fan说这是"机器人的GPT-2时刻"。
01:11:00 实验室里的Demo:精修画面和真实世界之间隔了多少次摆拍?
我们不知道是不是遥操摆拍了十多次,最终给你剪一段出来。
Generalist(GEN-1)放出6个特定任务99%成功率,背后是50万小时人类动捕数据。仔细看:只有T恤折叠、吸尘器维护这6个任务到了99%。其他任务泛化能力未知。全程没有语言参与——"没有语言就没有目标,机器人其实不知道自己在干什么。"
Genesis AI(GENE-26.5)打蛋、切番茄、做奶昔,多数子任务90-95%。打蛋和刀转移番茄两项最难的只到50-60%——打蛋刚好是"特别讲究触觉和手感"的动作,这两项做不好,离真实厨房还很远。公司自己说的是"30秒复杂技能=几小时人类数据+不到半小时机器人执行数据",路径是人类预训练+少量机器人适配+仿真闭环(他们原本就是仿真平台出身)。
Figure(Helix-02,5月8号放出)双机协同卧室整理:开关门、挂衣服、收耳机、倒垃圾、推椅子、盖被子,不到2分钟。画面精美,布景专业,打光讲究,像一个广告片。"考虑到今天机器人的遥操如此普及,我们不知道它真实的能力边界在哪里。"
这三个Demo都是在实验室条件下精挑细选的展示。播客前半段聊的那三台机器——自变量保洁干3小时死机、Aescape一周坏四天、Vbot机器狗遛狗体验——是任何普通人都能上手体验、看到所有失败和局限的真实产品。精选画面和完整工作日之间,差的不是技术参数,是"能不能在全天候、无人值守的条件下持续工作"这道最硬的门槛。
相关视频:
Generalist AI发布GEN-1!一脚踹开“精通物理任务”的大门,1小时数据,成功率达到99%_哔哩哔哩_bilibili
Genesis www.bilibili.com
Figure的demo www.bilibili.com
人物:
托马斯白 - “脑放电波”主播,消费电子营销人,科技媒体特约作者
Nixon - ”脑放电波“主播,硬件产品经理,前媒体记者
剪辑制作:Jeff
欢迎订阅脑放电波,2024/25苹果播客周度推荐节目、小宇宙累计13次编辑推荐单集、2024CPA播客中文奖年度科技数码类播客


欢迎在评论区留言发表你对 机器人做家务 的感受与看法
对于节目话题的更多观点,获取更多未呈现在节目中的扩展阅读,欢迎添加脑放电波小助手微信(BrainAMP01),附言“机器人”,加群参与讨论,后续会发布本期节目的文字稿
节目中用到的音乐:来自monkeyman535的90's Rock Style,地址freesound.org;来自kjartan_abel的Berlin Town,地址freesound.org;基于 CC BY 4.0 DEED 使用。
脑放电波往期节目精选(搜索关键词可收听)
AI 造物:3D打印机 / 3D打印的"iPhone时刻" / 3D扫描、生成与打印 / AI玩具和国产芯片
AI 应用:闪念贝壳
饮食健康、现代病人:AI助推造神 / 生物骇客 / AI 内容真假难辨 / 控糖革命 / 信息过载 / 长寿革命 / 阿斯巴甜致癌疑云
苹果特权:腕上革命 / 设计哲学 / 苹果供应链迷思 / 苹果广告底层逻辑 / iPhone 15 和它的前任们 / 苹果零售店
AI 相关节目:人机交互的与“iPhone 时刻” / 会喘气的AI语音里藏着下一代交互范式 / 解构Apple Intelligence / 和李楠聊AI硬件 / 611款 AI 生产力工具;
脑放电波是一档关注科技前沿、品牌营销和个人成长的谈话类节目。每期带给您一个有趣有据的话题,帮您在信息严重过载的现代世界小幅自我迭代。您可以在小宇宙、苹果播客或者其他泛用型播客客户端搜索“脑放电波”找到并关注我们,如果您对本期节目有任何疑问,欢迎您给我们留言,如果您觉得这期内容对你有所帮助,欢迎您关注点赞收藏转发,这对我们非常重要。
Avsnitt sparat!
Du hittar sparade avsnitt på Mina sidor.
Kunde inte spara avsnitt
Något gick fel. Försök igen.