
Dela
(see full author list at the end)
PAPER LINK
About a year ago, METR showed that the length of tasks frontier models can reliably complete doubles every few months. A related safety-relevant question is this: what length of tasks can models complete without any chain of thought (CoT)?
If models can do extensive reasoning without outputting any CoT, it would have implications for safety. Developers and deployment-time monitors couldn’t easily understand models’ motivations and catch dangerous planning. Models that reason substantially without a CoT might also drift further from human patterns of thought, since their reasoning is no longer constrained by text in the pretraining prior. As a result, they would be harder to understand and might be more likely to scheme.
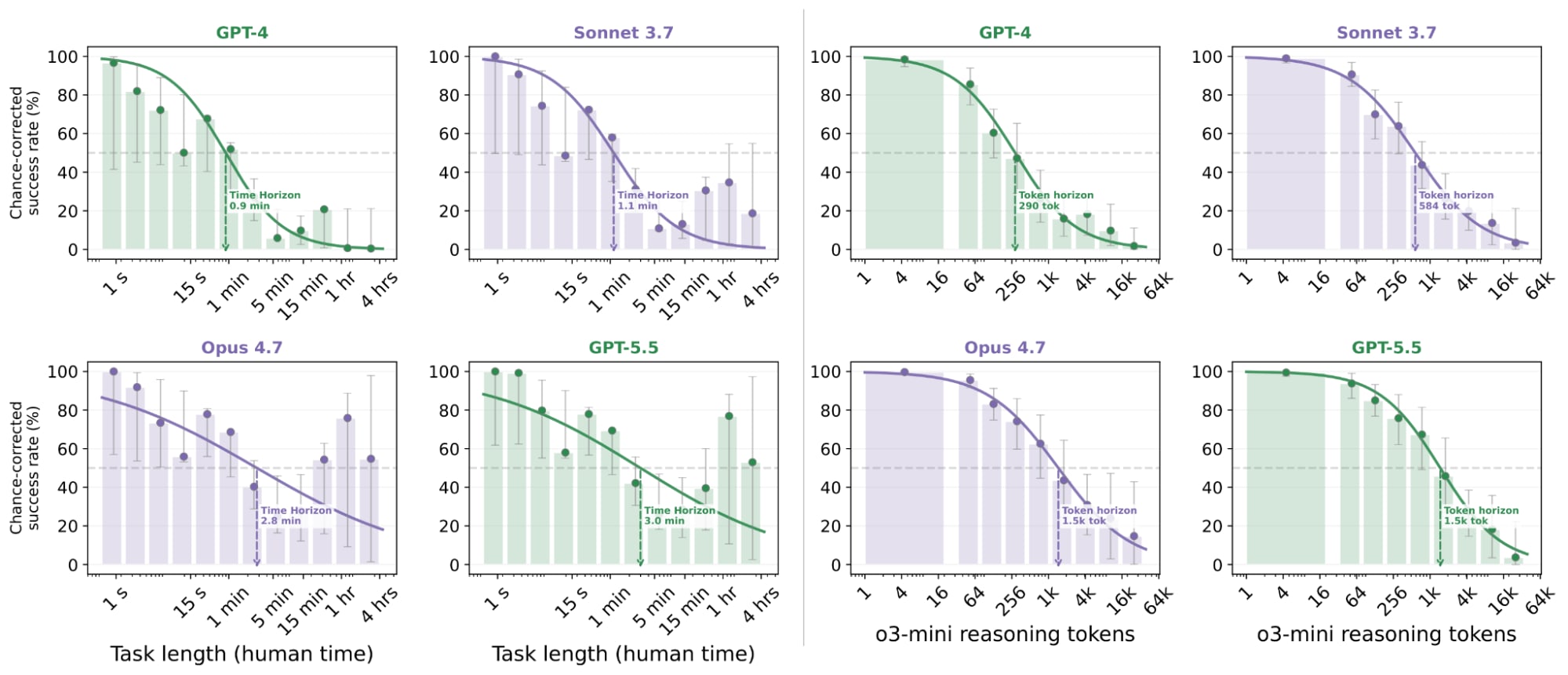
Extending Ryan Greenblatt's research, we investigate this by measuring models' ability to complete tasks without any CoT on a suite of 43 benchmarks spanning different domains. We compare AI reasoning ability to humans using the estimated 50% time horizon (TH)---the typical time taken for a human to perform a task that the LLM performs with 50% success rate. We find that frontier models like GPT-5.5 answer questions that take humans roughly three minutes with 50% reliability, and [...]
---
Outline:
(02:20) Methods
(04:59) Results
(06:47) FAQ
(08:21) Conclusion
---
First published:
June 10th, 2026
Source:
https://www.lesswrong.com/posts/SieLowPgNgRSPGhFw/estimating-no-cot-task-completion-time-horizons-of-frontier
---
Narrated by TYPE III AUDIO.
---
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.Avsnitt sparat!
Du hittar sparade avsnitt på Mina sidor.
Kunde inte spara avsnitt
Något gick fel. Försök igen.